
Photo by Luca Bravo on Unsplash
Demystifying Kafka: Understanding Producers, Consumers, Brokers, and More


Table of contents
Apache Kafka is a distributed stream processing system that was developed by LinkedIn using Java and Scala. It is a distributed append-only event log streaming system that can send, store, and transfer real-time data with high throughput.

One way to think of Kafka is as a big, distributed pipe that allows different servers to send messages to one another in a scalable and reliable way for as long as needed. Kafka can transfer large numbers of records in a short amount of time, much like a very large pipe moving liquid. The larger the diameter of the pipe, the larger the volume of liquid that can move through it.

When someone says that Kafka is fast, they are usually referring to its ability to move a lot of data quickly. Many design decisions contribute to Kafka's performance, but one of the main reasons for its speed is its use of sequential I/O. Sequential I/O refers to the way that data is stored and accessed on a hard drive. Random access is slow because the arm of the hard drive needs to physically move to different locations on the disk, while sequential access is much faster since the arm doesn't need to jump around. Kafka uses an append-only log as its primary data structure, which adds new data to the end of the file in a sequential pattern. This allows Kafka to take full advantage of the faster sequential I/O.
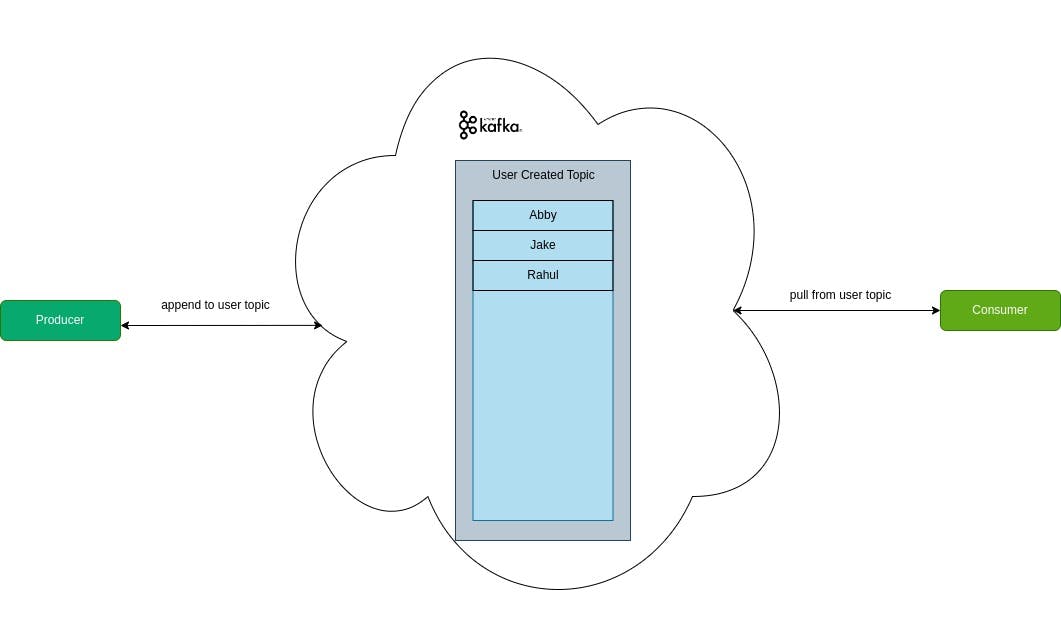
The producer in Kafka is responsible for sending data to brokers for storage and processing. This data is represented as an event, such as when a user creates or updates real-time data from an IoT device. The producer sends these events to a table called a Kafka topic, in this case, the topic is "user created". Producers can be configured to send messages synchronously or asynchronously.
Kafka brokers/servers run on port 9092 by default and are responsible for storing and managing a part of the data in Kafka. Brokers receive messages from producers, which are then stored in their local disk as a commit log, an append-only data structure that cannot be modified or deleted. A broker can store data for one or more topics.
Consumers in Kafka are clients or receivers that consume messages from a broker. They consume data in a pull-based approach, known as "polling", which means that the consumer keeps on requesting data from the broker from time to time. In this example, the producer first sends the user "Abby", then "Jake", and finally "Rahul" to the broker. The broker stores them in the order they were sent, and the consumer reads the data in the same order.
Topic partitioning and replication:
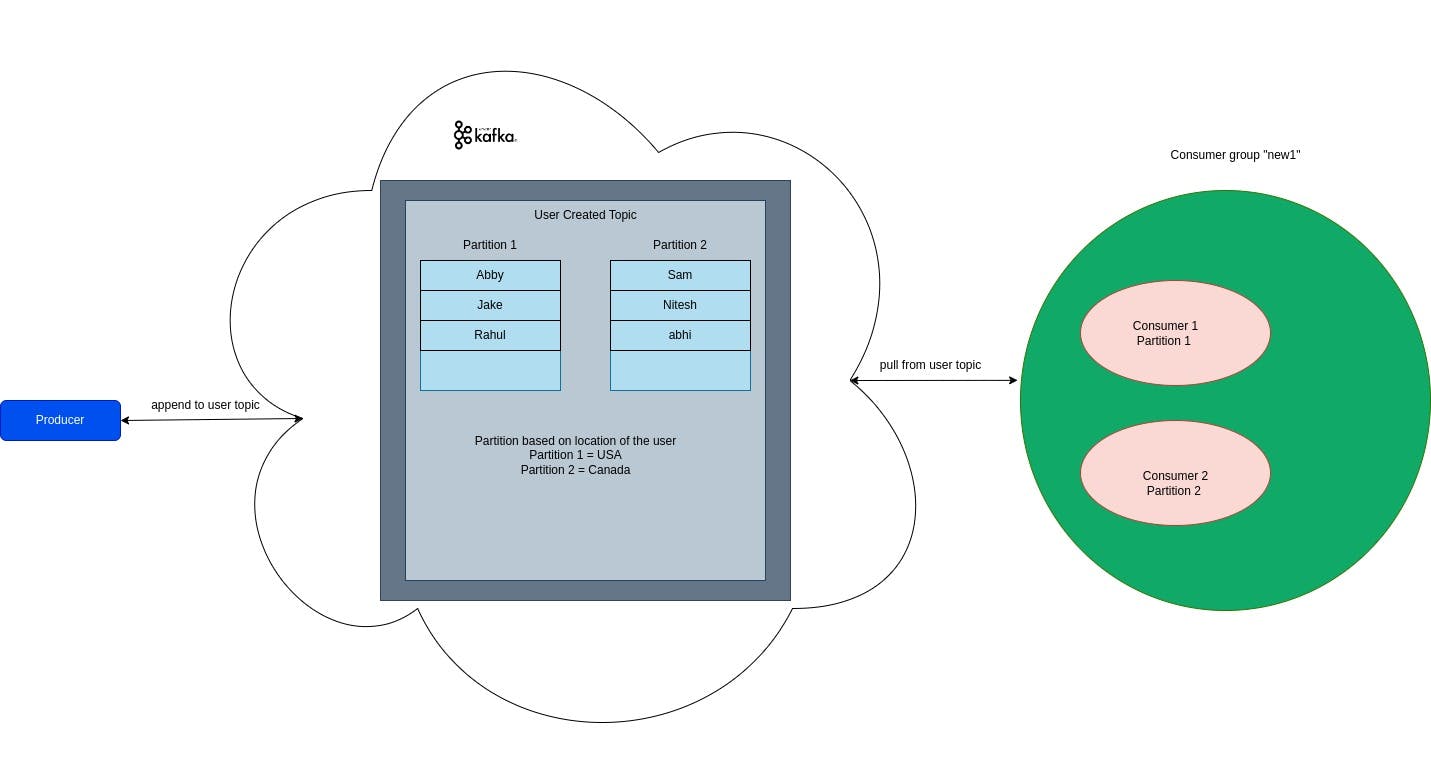
Kafka topics can become too large, but we can scale them using topic partitioning (and replication). This is similar to sharding in databases, and it helps distribute data among different partitions. Partitioning makes it easier to manage and query large datasets. However, this introduces complexity for consumers and producers, as they need to know which partition to read and write from. Additionally, brokers can have multiple replicas in the form of leaders and followers.
In the above example, let's consider a topic called "user created" with two partitions: "partition 1" and "partition 2". The producer can have logic to send data to either partition 1 or partition 2 based on the user's country or location of registration. If the producer sends data without any partition information, the data will be sent to a partition based on a "round-robin" logic. In this case, partition 1 contains all users from the USA, and partition 2 contains all users from Canada.
If there is only one consumer and two partitions, then the consumer will consume data from both partitions as there is no other consumer available.
Consumer groups:
When a Kafka topic has multiple partitions, a consumer group is used to collectively consume data from one or more partitions. Each partition can only be consumed by one consumer at a time, but multiple partitions can be consumed by multiple consumers in a consumer group. This results in high throughput and efficient processing of data. If a consumer fails, another consumer in the same group can take over processing the partition from where the previous consumer left off. In the example, consumer 1 of the group new1 will consume partition 1, and consumer 2 of the same group will consume partition 2 respectively.
ZooKeeper:
However, Kafka doesn't handle the assignment of partitions to consumers in a group or which consumer will handle which partition of the topic, especially if there is a replication of the topic partition. This is where ZooKeeper comes into the picture. ZooKeeper is a distributed system that helps manage and coordinate distributed applications, including Kafka. Zookeeper is a crucial component of Kafka as it handles replication in Kafka and keeps track of details such as who is the leader of the replication/topic/partition. It is also responsible for managing Kafka's consumer groups and their associated metadata. In this blog, we will discuss three APIs of Kafka: the server admin API, producer API, and consumer API.
Let's spin up our kafka+zookeeper locally
create a file name docker-compose.yml
version: '2'
services:
zookeeper: # name of the container
image: confluentinc/cp-zookeeper:latest # name of the image we #want to pull from dockerhub
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181 # port on the system: port of docker
kafka: # name of the container
image: confluentinc/cp-kafka:latest # name of the image we want #to pull from dockerhub
depends_on:
- zookeeper # here we're kinda importing/refering this image
ports:
- 29092:29092 # port on the system: port of docker
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
Zookeeper Service:
the environment variables specify the client port and tick time. The ZOOKEEPER_CLIENT_PORT variable sets the port number that clients use to connect to ZooKeeper.
ZOOKEEPER_TICK_TIME sets the length of a single tick in milliseconds.
Kafka Service: KAFKA_BROKER_ID sets the unique identifier of the Kafka broker. KAFKA_ZOOKEEPER_CONNECT specifies the ZooKeeper instance that Kafka uses for coordination.
KAFKA_ADVERTISED_LISTENERS specifies how Kafka can be reached from outside the Docker network. PLAINTEXT://kafka:9092 indicates that the Kafka broker can be reached at kafka:9092 from within the Docker network, while PLAINTEXT_HOST://localhost:29092 indicates that the broker can be reached at localhost:29092 from outside the Docker network. The KAFKA_LISTENER_SECURITY_PROTOCOL_MAP variable sets the security protocol for each listener. PLAINTEXT indicates that the listener uses plaintext, while PLAINTEXT_HOST indicates that the listener is exposed to the host machine.
KAFKA_INTER_BROKER_LISTENER_NAME specifies the listener used for communication between Kafka brokers. KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR sets the replication factor for the Kafka internal topic used to store consumer offsets.
There are many APIs in Kafka but we're gonna cover just three of them in this article.
Admin API: to create topics and partitions
Producer API: to send messages/events in topic/partition
Consumer API: to receive messages from topic
install npm package kafkajs
npm install kafkajs
Admin API: to connect and create topics inside kafka broker
import {Kafka} from "kafkajs";
const TOPIC = "user_created";
const NUM_PART= 2;
export const runkafka = async (topic:string,numPart:number) => {
try {
const kafka = new Kafka({
"clientId": "myapp1",
"brokers":["localhost:29092"], // kafka broker ip
})
const admin = kafka.admin() // call admin api
await admin.connect(); // connect to admin
console.log("Connected");
admin.createTopics({
"topics":[{
"topic":topic, // topic name
"numPartitions":numPart // number of partitions in //that topic
}],
});
await admin.disconnect()
console.log("Topic created");
return
} catch (error) {
console.log(`err in kafkajs ${error}`);
return;
}
}
runkafka(TOPIC,NUM_PART)
Producer API: to send data to kafka broker
const TOPIC = "user_created";
const NUM_PART= 2;
export const producer = async (part:number,value:object) => {
try {
const kafka = new Kafka({
"clientId": "myapp1",
"brokers":["localhost:29092"]
})
const producer = kafka.producer()
await producer.connect();
console.log("Connected");
const data = await producer.send({
"topic":TOPIC,
"messages":[
{
"value":JSON.stringify(value), // data you want to // push
"partition": part // partition you want to push
}
]
})
await producer.disconnect();
console.log("producer created", JSON.stringify(data));
return data;
} catch (error) {
console.log(`err in kafkajs ${error}`);
}
}
interface userInfo {
name: String,
location: String
}
enum location {
USA= "usa",
CANADA= "canada"
}
const user: userInfo={
name:"jake",
location: "usa"
}
const part = user.location == location.USA ? 0:1;
producer(part,user)
Consumer API: to consume data from partition
export const consumer = async () => {
try {
const kafka = new Kafka({
"clientId": "myapp1",
"brokers":["localhost:29092"]
})
const consumer = kafka.consumer({"groupId":"test"}) // mention // the consumer groupid
await consumer.connect();
console.log("Connected");
await consumer.subscribe({
"topic":"user",
"fromBeginning":true, // you can get message from
})
await consumer.run({
"eachMessage": async (res)=>{
console.log(`message ${res.message.value} from partition ${res.partition}`);
}
})
await consumer.disconnect()
console.log("consumer created");
} catch (error) {
console.log(`err in kafkajs ${error}`);
}
}
consumer()
You can checkout my project related to kafka here
Summary
The article provides an overview of Apache Kafka, a distributed stream processing system used to send, store, and transfer real-time data with high throughput. Kafka uses a distributed append-only event log streaming system to send messages in a scalable and reliable way. The article explains that Kafka's performance is due to its use of sequential I/O, which allows it to take full advantage of faster sequential access. The article also describes Kafka's architecture and how it uses producers, brokers, and consumers to send and receive data. The article then discusses Kafka topics and how partitioning is used to distribute data among different partitions. Finally, the article introduces ZooKeeper, a distributed system used to manage and coordinate distributed applications, including Kafka.
Reference: Kafka website, Youtube